First some fun facts:
I can read Chinese perfectly, but writing is difficult, I don’t remember the details of many characters, especially the low frequency ones. I just have in mind a rough shape. When I type, I use a Pinyin input method, but by now it doesn’t really rely on phonemic awareness, it’s just how you would type automatically while thinking.
Although I’ve never been taught to read or recognise them specifically, I can read traditional Chinese characters with no trouble at all, for example, newspapers in Hong Kong or Taiwan. I can also read most Japanese kanji, even when the details of the characters are actually quite different, for example: 开发 vs. 开发 vs. 开発。
Though there are many characters (3,500 for basic use), there are only a handful of radicals. See: Chinese Radicals. Like many nice things, they fit on one page:

Since there are no clusters and you can only have /n/ or /?/ as codas, the number of possible syllables (what any character could sound like) is also very limited (and then, many are possible but not used, i.e. “lexcial gaps”)。
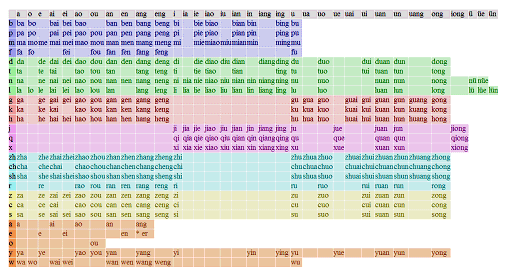
Just like there are loads of Latin terms I’ve never learned, I can guess what they sound like and that it’s probably a plant, or an animal, or something specific from the context. Look. here’s the Periodic Table in Chinese, for almost all of these characters, it’s not specifically learned, and I can guess what it sounds like, that it’s probably an element, I could even guess the group(s) its in (e.g. metal or gas)。
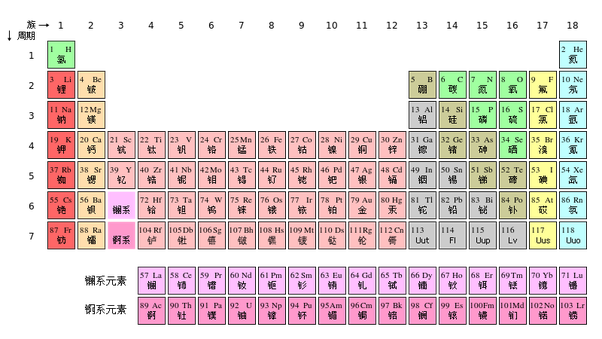
Therefore, if by “learn” or “know”, you mean receptive use, i.e. recognising the characters. I estimate that the best results would be upwards of 3,500 per year; provided that:
First, you become very familiar with the radicals, and the composition geometry of characters (if you are asked to design a novel character, you would know how to go about it)。
Then, you have a psych lab grade training system, which tracks the radical elements, lexical data, frequencies, and your progress. Imagine a Leitner box, where you progress through the most useful characters, building up from simpler ones, with more repetitions for the ones you miss; and you can have hundreds of characters flashing before you within a single session, prompting quick response for sound or lexical pairing.
I gave the optimistic number because this process is hardly linguistic, and research in biopsych produced way more impressive results then in ESL stats. Just imagine a test where hundreds of pictures of cityscape, landscape, nature and various themes flash before you at 50ms each, and you are ask to press a button when ever you see a face or a chimp, you can do it! Here we are talking about the limit of the throughput of your coginition. And if we had a training sequence that could exploit this capacity, it’s more than enough.
The above would only be effective if you pair it with level-appropriate reading. Say you read short pieces that are largely based on characters you just learned. The selection has to be fine-grained to have a very specific grade for your level.
I estimate that with about 10x sessions of around 10 minutes each for the automated training per day, plus 3 sessions of 20-minute level-matched reading, at 5 to 6 days per week, you can get at least 3,000 characters in about 50 weeks.
Perhaps it’s really quite attainable, considering many people have mastered this:

EDIT
Now after thinking about it, I think such high numbers are more than likely achievable, based on several things I’d like to add:
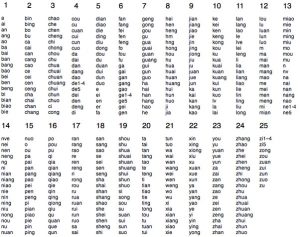
1.The syllables follow a frequency distribution, with only a handful of the most frequent types making up almost all the occurences you would encounter. If you play them on a randomised loop, it would only take a few minutes at 1.0x speed, and even faster at say, 1.5x or 2.0x. This way it’s possible to go through the syllables hundreds of times in a week to familiarise yourself with them.
2.The characters also follow a frequency distribution, effectively dividing into several “grades”. Here’s an example with kanji:
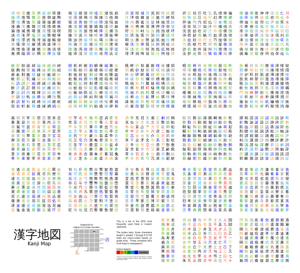
3.Subsequently the radicals that occur in these graded characters also follow a frequency distribution. And the training should give more emphasis on the most useful ones.
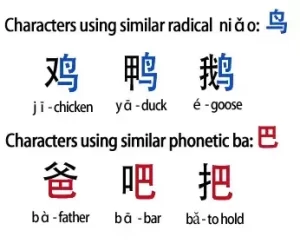
4.For visual training, you could have a matrix of characters, drawn from a subgroup sharing some radical or component. Then you have to identify and match them — once you find a match, a sound for that character should be played to aid association:

5.This process can be integrated with eyetracking, and you only have to use fixations to navigate the characters. The eyetracking data can also reveal your recognition through “jumps” and duration of fixation.

6.Once you are familiar with the character, the training can move onto the semantic association stage. You can combine the characters left and right in a meaningful context, which serves as recognition, semantic memory, and reading training rolled into one.
