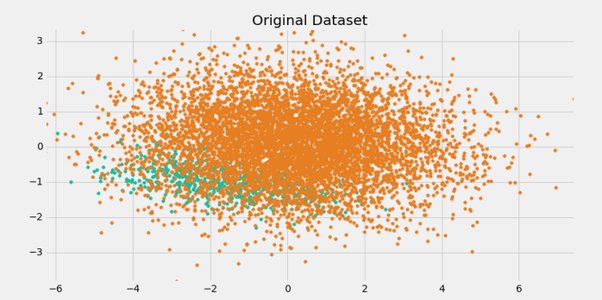
They are victim to what we call “data imbalance.”

Specifically, Cantonese is WAY less prevalent than Putonghua. You’re far more likely to meet somebody who speaks Putonghua but not Cantonese (1.32 billion people) as opposed to somebody who speaks Cantonese but not Putonghua (0.08 billion people).
When Category A outnumbers Category B sixteen to one – i.e. 94% of all data points train to “A” – the model will simply categorize everything as “A”. You’ve constructed not just a useless model, but a model that gives you an incorrect answer.
(An extra link specifically talking about ways to deal with data imbalance).
—
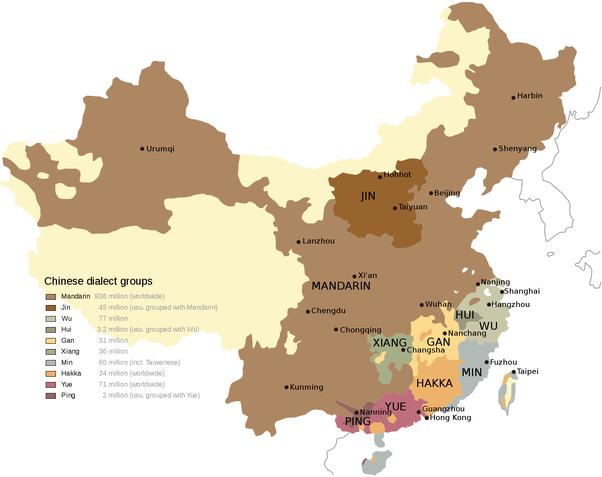
Here’s the dialect map of Chinese. Notice how much larger the Northern Tongues (labelled “Mandarin”) is compared to the Southern Tongues (everything else other than Jin). Cantonese is a dialect of the Yue dialect family, that’s the part colored in red.
The reality is that no dialect is any easier or harder than any other dialect. There are certain aspects that a speaker of one would struggle with on the other, but children will pick up a tongue in the same speed. A Putonghua speaker would struggle with the extra tones in Cantonese, but a Cantonese speaker would struggle with the extra consonants in Putonghua.